RAG Content Pipeline — это входная точка в проектный раздел о том, как превратить разрозненные документы, страницы и изображения в базу знаний, с которой уже можно разговаривать через чат или API. В центре здесь связка двух репозиториев: PFRAG и RAG. Первый приводит контент в пригодный для индексации вид, второй отвечает за поиск, хранение контекста и диалоговый слой.
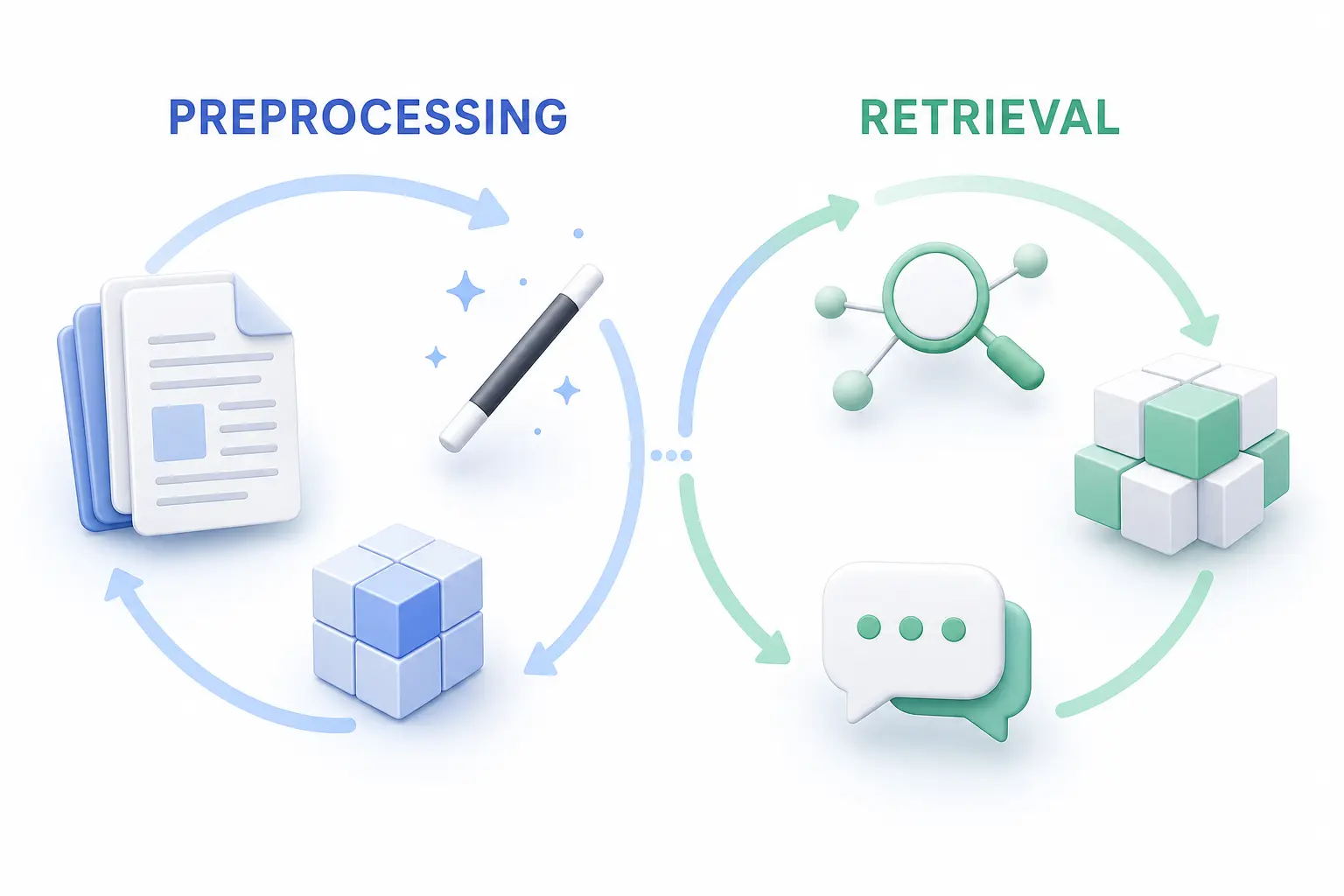
Главная мысль раздела простая: качество RAG начинается не в моменте ответа модели, а гораздо раньше — там, где сырой материал вытаскивают из PDF, сайтов, презентаций и изображений, очищают, приводят к Markdown и избавляют от дублей. Если этот этап пропустить или сделать формально, даже сильный retrieval будет опираться на шумный, повторяющийся или плохо размеченный текст.
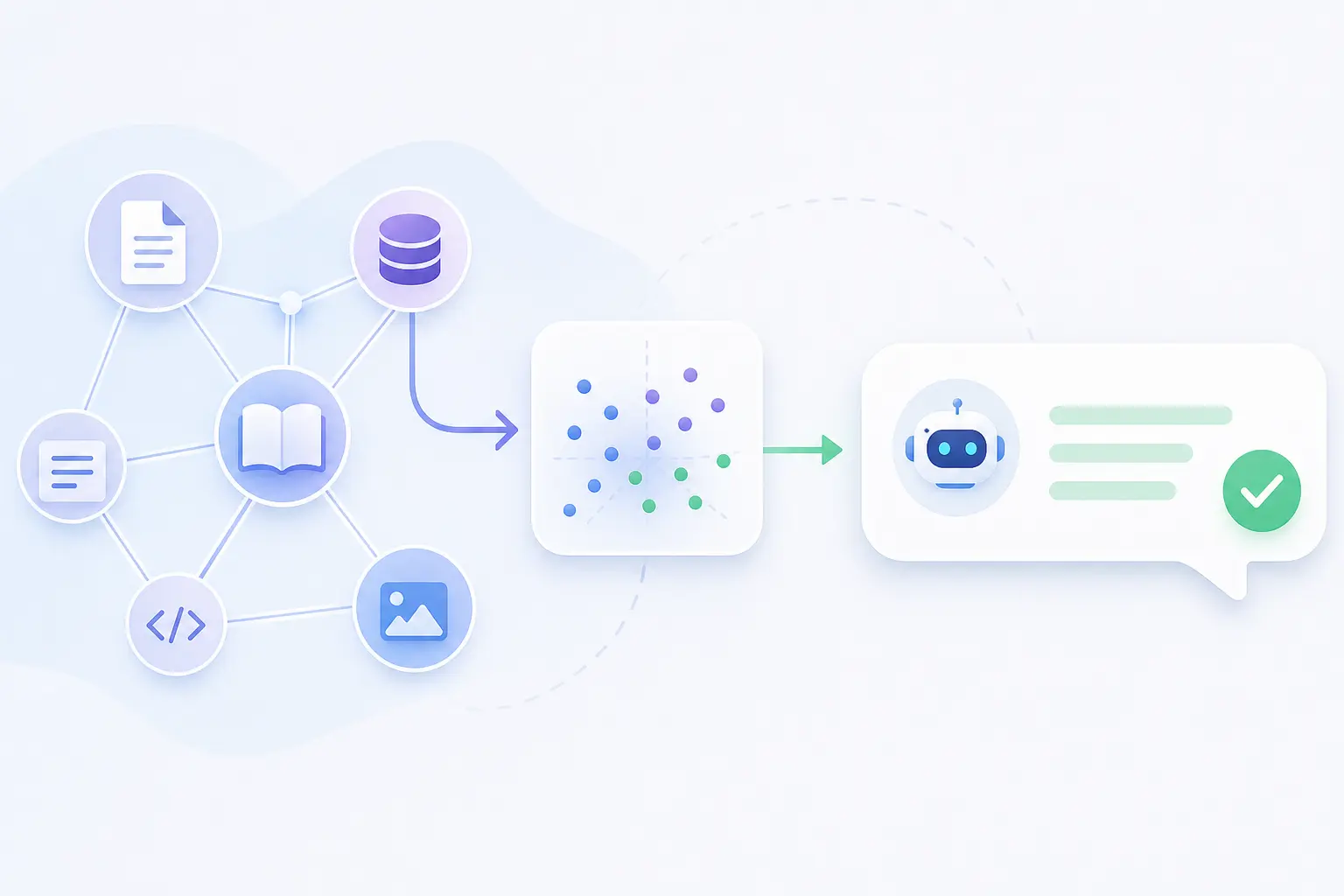
PFRAG закрывает подготовительный контур. Он принимает PDF, DOCX, PPTX, изображения, HTML, TXT и URL, вытаскивает текст в Markdown, запускает OCR, очищает результат через LLM, объединяет файлы и убирает дубли. Для читателя это та часть системы, где хаотичная папка с материалами постепенно становится аккуратным корпусом знаний, который не стыдно отдавать на индексацию.
RAG отвечает за контур поиска и диалога. Он принимает подготовленные документы, индексирует их через LightRAG, хранит векторный слой в Qdrant, граф знаний в Neo4j, а метаданные и историю чата — в PostgreSQL. Для запросов доступны режимы naive, local, global и hybrid, а ответы можно получать через REST, SSE-стриминг или WebSocket. То есть это уже прикладной слой: вопросы к базе знаний, multi-turn контекст и подключение чатов, ботов или внешних сервисов.
Как устроен pipeline
Основной сценарий выглядит так:
- Источники: документы, изображения, HTML-страницы и сайты.
- Подготовка: загрузка файлов, BFS-парсинг сайтов, скачивание найденных документов.
- Очистка и дедупликация: OCR, Markdown extraction, LLM cleanup, named prompts, векторная и построчная дедупликация.
- Ingestion: отправка очищенного Markdown в RAG-контур.
- Индекс: чанки, эмбеддинги, Qdrant, графовые сущности и связи в Neo4j.
- Чат/API: вопросы по базе знаний, multi-turn контекст, REST, SSE или WebSocket.
Такое разделение удобно не только архитектурно, но и по-человечески: людям, которые отвечают за материалы, нужен понятный операционный контур для подготовки и контроля базы знаний; сервисам и интерфейсам нужен стабильный backend для retrieval, индексации и диалога. Поэтому PFRAG можно развивать как рабочее место для редакции базы знаний, а RAG — как основу для чатов, ботов и внешних интеграций.
Подробнее
- От сырых документов к базе знаний — общий маршрут по системе: от файлов, сайтов и изображений до индекса и чата.
- Архитектура двухконтурной RAG системы — зачем разделять preprocessing/operations и retrieval/chat backend, чтобы не смешивать подготовку контента с пользовательскими запросами.
- Качество данных перед индексацией — почему OCR, Markdown, LLM cleanup, промпты, дедупликация и chunking напрямую влияют на то, какой контекст получит модель.
- Hybrid Retrieval на LightRAG — как LightRAG, Qdrant, Neo4j, PostgreSQL, query modes и streaming-чаты складываются в поисково-диалоговый контур.
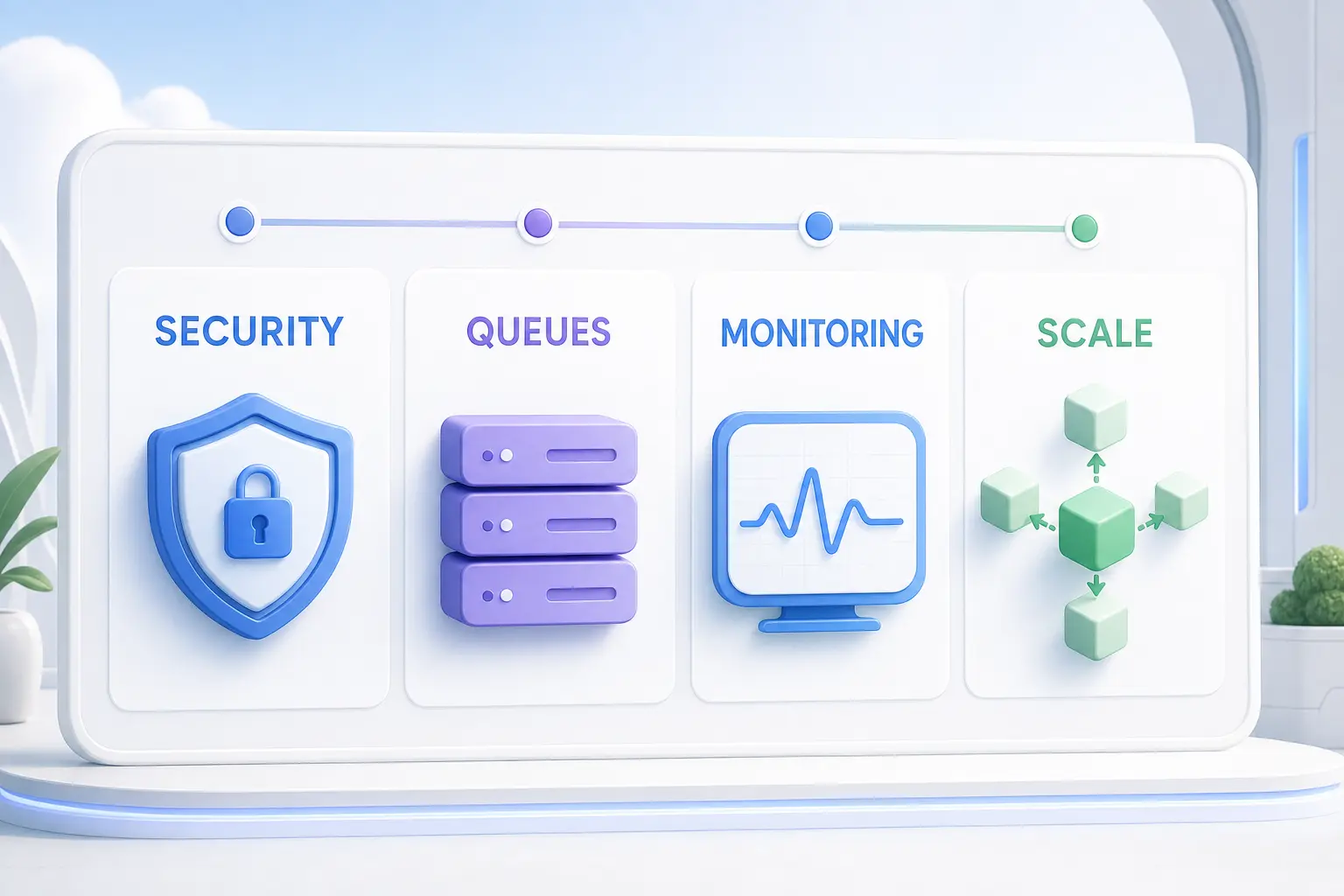
- Roadmap production ready RAG — какие инженерные темы остаются на пути к production-ready системе: очереди, безопасность, миграции, мониторинг, re-ranking, фильтры и масштабирование.