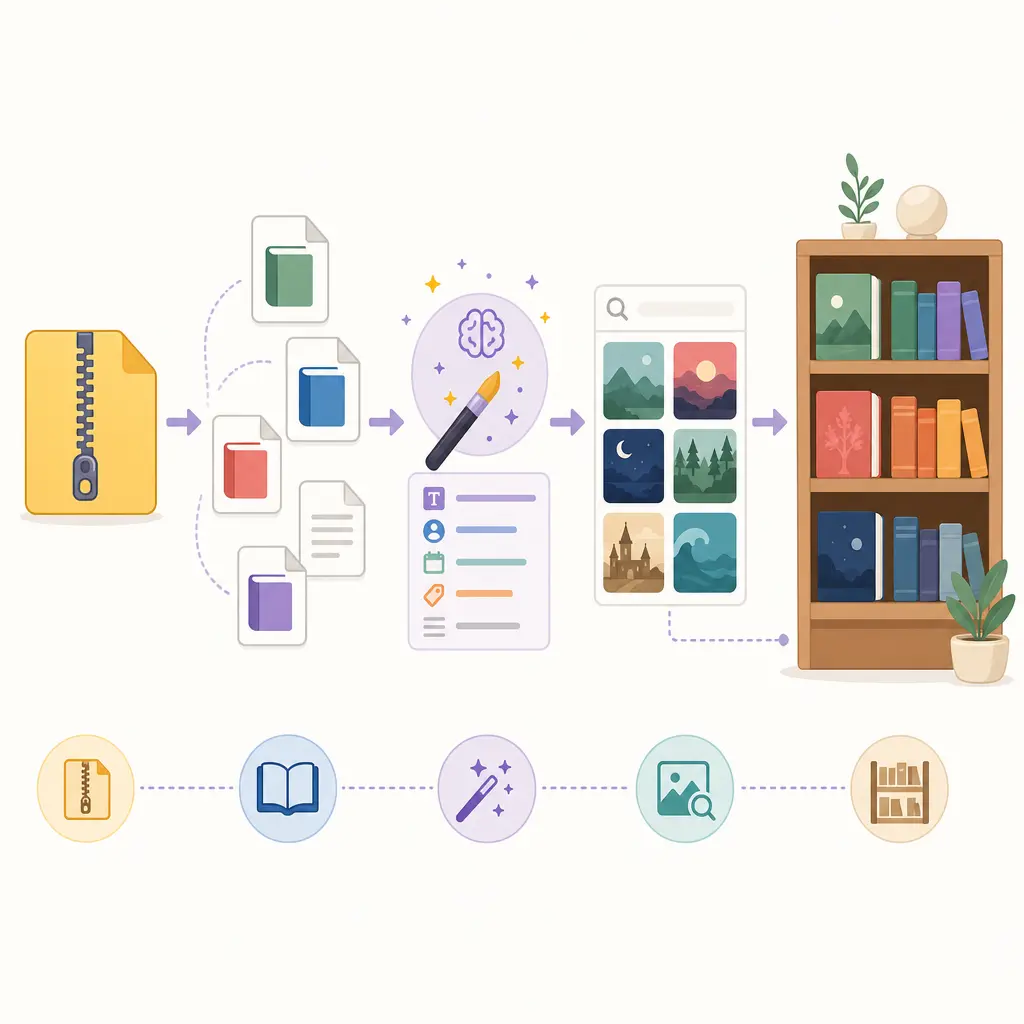
BOOK-LIBRARY — веб-приложение для частной электронной библиотеки: место, где разрозненные книги превращаются в понятный каталог, а работа с файлами не сводится к ручному перекладыванию папок. Проект вырос из простого каталога с загрузкой книг в систему с несколькими рабочими поверхностями: публичной витриной для читателя, отдельной React-админкой для операционной работы и backend-слоем, который держит файлы, SQLite, очереди импорта, переводы и временные ссылки на скачивание.
Проект не пытается быть книжным маркетплейсом или социальной сетью для отзывов. Его задача проще и практичнее: помочь аккуратно собрать коллекцию, проверить данные при пополнении, не терять контекст между импортом, переводами и публикацией, а читателю дать спокойную навигацию по категориям, карточкам и опубликованным переводам.
Эта страница работает как входная карта проекта. Ниже собраны основные части BOOK-LIBRARY и ссылки на подробные материалы: от пользовательских сценариев и импорта до архитектуры, Quartz-интеграции, React-админки, LLM-переводов и roadmap. Если нужен общий смысл — начните здесь; если интересен конкретный слой системы — переходите к соответствующей статье в блоке «Подробнее».
Три поверхности продукта
На BOOK-LIBRARY удобно смотреть как на несколько интерфейсных слоёв, каждый из которых закрывает свой способ работы с библиотекой:
- публичная SvelteKit-витрина для чтения каталога;
- React-админка как основной операционный центр;
- legacy EJS UI внутри backend для простого HTML-доступа и совместимости.
Публичная часть отвечает за читательский маршрут: от дерева категорий и breadcrumbs к подкатегориям, счётчикам книг по веткам и страницам книг внутри выбранной категории. Книги в категории отдаются постранично: API поддерживает limit, offset, hasMore и total, а старый формат оставлен через format=legacy или all=1.
React-админка стала целевой админской поверхностью — местом, где библиотека пополняется, проверяется и приводится в порядок. Старая Svelte-admin часть удалена, чтобы не держать две конкурирующие админки. В React вынесены dashboard, операции импорта, внешний поиск, переводы, настройки, управление LLM-провайдерами и security-настройки.
Backend как рабочий слой
Backend на Express обслуживает не только публичный API. На нём держатся:
- SQLite-база с книгами, категориями, пользователями, сессиями, задачами и переводами;
- uploads для книг, обложек и временных файлов;
- временные download-токены вместо прямых ссылок на файлы;
- durable jobs для долгих операций;
- import queue и polling прогресса;
- production-hosted bundle React-админки;
- CORS-разделение публичных и admin origins;
- CSRF-защита для state-changing admin API.
Именно этот слой связывает «витрину» с реальной операционной жизнью библиотеки. Долгие операции больше не завязаны на один HTTP-запрос: одиночный импорт, batch ZIP, поиск и импорт из Anna’s Archive и Flibusta, а также LLM-переводы оформлены как задачи с устойчивым состоянием и polling. Это проще поддерживать, чем поток, который должен жить до конца обработки, и понятнее для админки: у каждой долгой работы есть статус, прогресс и точка возврата.
Импорт, поиск и обложки
Импорт — это мост между внешними источниками, локальными файлами и аккуратной карточкой книги в каталоге. Каталог можно пополнять вручную, через ZIP-архивы и через внешний поиск. В React-админке общий SearchPage объединяет Anna’s Archive и Flibusta: администратор ищет книгу, смотрит найденные варианты и запускает импорт как задачу.
Для карточек сохраняется обычная ручная правка, но часть рутинной работы автоматизирована. Есть сопоставление категорий, обработка дублей, извлечение метаданных и интеллектуальная замена обложек: система показывает candidates, даёт preview и только после этого заменяет cover. Поэтому импорт здесь описан не как разовая кнопка «загрузить», а как отдельный рабочий процесс с проверкой результата.
LLM-провайдеры и переводы
LLM-провайдеры вынесены из кода в управляемую runtime-сущность в SQLite. Их можно включать, выключать, расставлять по priority и использовать с fallback, не меняя код при каждом переключении модели или endpoint.
Переводы книг оформлены как отдельный pipeline, а не как один prompt. Это важно для длинных текстов: задача проходит ingestion, сбор canonical document, segmentation, batch-перевод, QA, сборку artifacts и ручную проверку. Администратор может смотреть сегменты, findings, повторять неудачные части, отменять задачи и публиковать или снимать результат. Публично видны только published EPUB/PDF artifacts.
Часть направления сознательно оставлена в deferred scope: OCR, production PDF renderer, извлечение медиа из DOCX/PDF, translation memory и бюджетные dashboards. Поэтому roadmap здесь важен не как список желаний, а как граница между уже описанной системой и тем, что пока не стоит считать готовой возможностью.
Связь с Quartz
BOOK-LIBRARY уже частично связан с этим Quartz-сайтом, но сайт не превращается в зеркало файлового каталога. В Quartz есть страница content/library.md, компонент quartz/components/LibraryPage.tsx, конфиг quartz/static/data/bookshelf.json, generated catalog quartz/static/generated/bookshelf-catalog.json и mirrored covers через quartz/util/bookshelfCatalog.ts.
Идея интеграции аккуратная: Quartz показывает отобранный каталог, подборки и заметки, а сами файлы остаются в BOOK-LIBRARY и скачиваются через временные токены. Это сохраняет разницу между сайтом с материалами и рабочей библиотечной системой: Quartz помогает рассказывать и показывать, BOOK-LIBRARY продолжает хранить, обрабатывать и выдавать книги.
Подробнее
Дальше материалы можно читать как карту проекта: сначала общий обзор, затем архитектура и отдельные рабочие контуры — импорт, админка, переводы, Quartz-интеграция и roadmap.
- Обзор и сценарии — как библиотекой пользуются читатель, администратор и оператор импорта.
- Архитектура — backend, публичная витрина, React-админка, SQLite, очереди, безопасность и деплой.
- Импорт, метаданные и каталог — как устроены задачи импорта, внешние источники, категории, дубли и обложки.
- React-админка и операционный центр — почему админская часть вынесена в отдельное приложение.
- LLM-переводы книг — pipeline переводов, проверка сегментов, artifacts и публикация.
- BOOK-LIBRARY и Quartz — как библиотека связана с этим сайтом без прямой публикации файлов.
- Roadmap — что уже закрыто и что остаётся следующим этапом.